





 Next Mile
Next Mile






Achieving Data Lake Success with Milemarker’s Expert Team and Done-for-You Approach


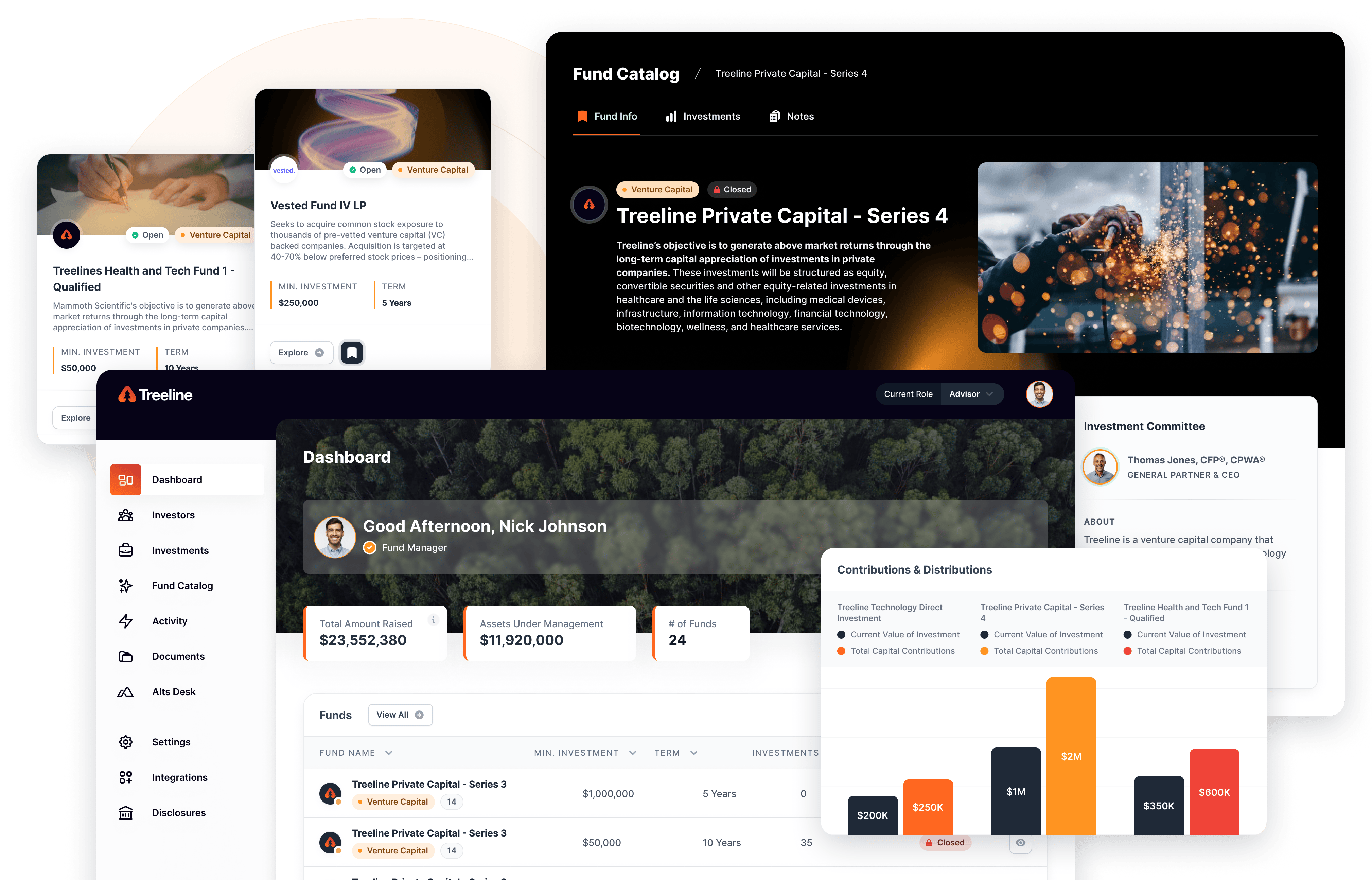
In the rapidly evolving landscape of wealth management and financial services, data has become the new currency. Firms are inundated with vast amounts of information from various sources—client profiles, market trends, regulatory updates, and more. The challenge lies not in collecting data but in harnessing it effectively to drive strategic decisions and gain a competitive edge.
Enter the data lake—a centralized repository that allows you to store all your structured and unstructured data at any scale. While the concept promises unparalleled insights and agility, the reality is that many organizations struggle to implement and maintain a successful data lake. That’s where Milemarker comes in. With our expert team and done-for-you approach, we eliminate the complexities and set you on a path to data excellence.
The Data Lake Dilemma
Implementing a data lake is not just a technological endeavor; it’s a strategic initiative that requires careful planning, expertise, and ongoing management. Common pitfalls include:
• Complex Integration: Connecting disparate data sources and systems is a daunting task.
• Data Governance Challenges: Ensuring data quality, security, and compliance is critical yet complicated.
• Resource Intensive: Building and maintaining a data lake demands significant time and technical expertise.
• Unrealized ROI: Without proper execution, the data lake can become a costly data swamp, yielding little to no return on investment.
Milemarker’s Solution: Expertise and Execution
At Milemarker, we understand the intricacies of data management in the financial sector. Our solution is designed to address the challenges head-on, providing a seamless, efficient, and effective data lake implementation.
Expert Team at Your Service
Our team comprises seasoned professionals with deep expertise in data engineering, cloud computing, and financial services. We bring:
• Strategic Guidance: We help define clear objectives aligned with your business goals.
• Technical Proficiency: Leveraging the latest technologies and best practices to architect your data lake.
• Regulatory Knowledge: Ensuring compliance with industry regulations such as GDPR, FINRA, and SEC guidelines.
Done-for-You Approach
We take the heavy lifting off your shoulders so you can focus on what you do best—serving your clients.
• End-to-End Implementation: From initial assessment to deployment, we handle every aspect.
• Seamless Integration: Our solutions connect effortlessly with platforms like AWS, Azure, Google Cloud, Local SQL, MySQL, and Postgres.
• Ongoing Management: Continuous monitoring, maintenance, and optimization to keep your data lake running smoothly.
Why Milemarker is the Right Choice
Proven Track Record
We have a history of successful implementations for firms of all sizes. Our clients have witnessed transformative results, including enhanced data accessibility, improved decision-making, and accelerated innovation.
“The partnership with Milemarker has been massively impactful for our ability to capture and more deeply analyze data across our rapidly growing number of accounts. Milemarker serves as a key partner for our future success. I highly recommend Milemarker to other advisors looking to enhance their tech stack and gain deeper insights from their data.”
— James Bogart, CEO of Bogart Wealth
Tailored Solutions
We recognize that each organization has unique needs. Our team works closely with you to customize the data lake to fit your specific requirements, ensuring maximum relevance and utility.
Maximized ROI
Our efficient processes and expert management mean you start reaping the benefits sooner. We focus on delivering tangible value, turning your data lake into a strategic asset rather than a sunk cost.
The Milemarker Process
1. Discovery and Assessment
• We evaluate your current data landscape, identify gaps, and define clear objectives.
2. Design and Architecture
• Our experts design a scalable and secure data lake architecture tailored to your needs.
3. Implementation
• We integrate your data sources, set up governance protocols, and deploy the solution.
4. Testing and Validation
• Rigorous testing ensures functionality, performance, and compliance.
5. Training and Support
• We provide comprehensive training for your team and ongoing support to ensure long-term success.
Comprehensive Integration Capabilities
Our data lake solutions are designed to integrate seamlessly with a wide array of systems and platforms:
• Cloud Services: Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP)
• Database Systems: Local SQL databases, MySQL, PostgreSQL
• Financial Software: Sage Intacct, Quickbooks, Great Plains, Expensify, Paycor, and many more.
• Customer Relationship Management (CRM): Salesforce, Redtail, Salentica, Wealthbox, EBix Smartoffice, and many more.
• Portfolio Management Tools: Orion, Black Diamond, Addepar, Envestnet, Tamarac, eMoney, MoneyGuide, and many more.
We continuously expand our integration portfolio to accommodate emerging technologies and platforms.
Security and Compliance at the Forefront
In the financial industry, data security and regulatory compliance are non-negotiable. Milemarker employs robust security measures, including:
• Data Encryption: Both at rest and in transit
• Access Controls: Role-based permissions and authentication protocols
• Regulatory Compliance: Alignment with standards such as GDPR, CCPA, and industry-specific regulations
Success Stories
Case Study: Transforming Data Management for a Leading Wealth Management Firm
Challenge: The firm struggled with siloed data systems, leading to inefficient processes and limited insights.
Solution: Milemarker implemented a fully managed data lake that unified their data sources and provided real-time analytics capabilities.
Result: Improved decision-making, increased operational efficiency, and a significant return on investment within the first year.
“Milemarker has transformed the way we handle our data. The seamless integration and fully managed service have saved us countless hours and resources. It’s like having an entire data team at our fingertips.”
— Laura Hubbell
Frequently Asked Questions
1. How quickly can Milemarker implement a data lake for our organization?
Implementation timelines vary based on complexity, but our efficient processes typically enable deployment within weeks rather than months.
2. Do we need to have in-house technical expertise to work with Milemarker?
No. Our done-for-you approach means we handle all technical aspects. We become an extension of your team, providing the expertise you need.
3. How does Milemarker ensure data security?
We utilize advanced security protocols, including encryption, access controls, and continuous monitoring, to protect your data. Compliance with regulatory standards is integral to our approach.
4. Can Milemarker integrate with our existing systems and software?
Yes. We design our solutions to be highly compatible and can integrate with a wide range of platforms, databases, and applications.
5. What kind of support does Milemarker offer post-implementation?
We provide ongoing support, including monitoring, maintenance, updates, and training to ensure your data lake continues to deliver value.
Take the Next Step Toward Data Mastery
The potential locked within your data is immense. With Milemarker’s expert team and done-for-you approach, you can unlock that potential without the usual obstacles and uncertainties.
Contact us today to schedule a consultation and discover how we can tailor a data lake solution that propels your organization forward.
