





 Next Mile
Next Mile






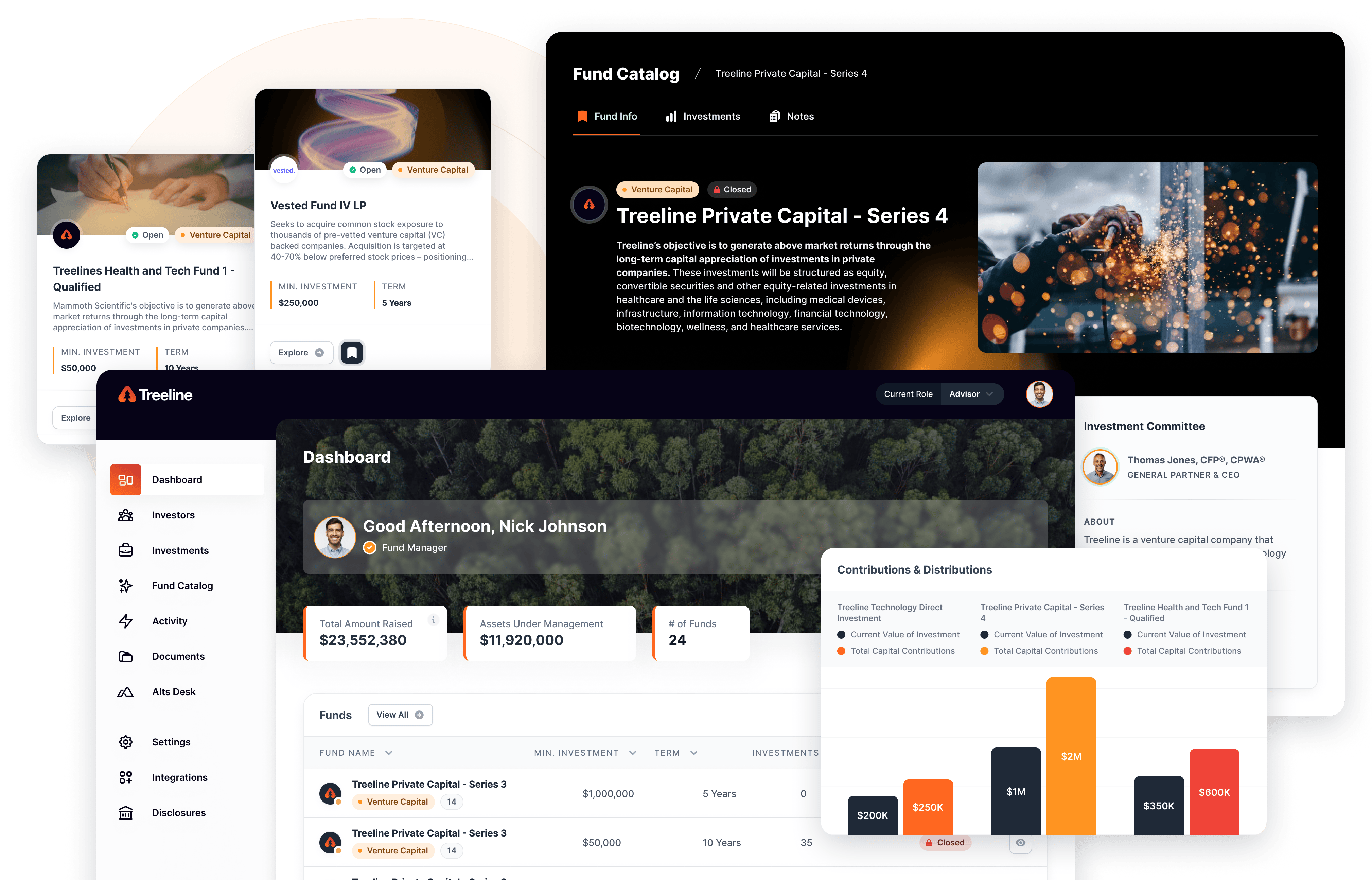
What is Data Normalization, and Why Does it Matter to You?


[vc_row][vc_column][vc_column_text]As a CEO, you likely have a lot of data at your disposal. After all, data is one of the most essential tools you have for making decisions about your company, how you serve your clients, and how you build your team. But have you ever stopped to think about how that data is organized? Is it easy to find what you’re looking for? Or is it a jumbled mess?
The answer to those questions could lie in data normalization. Data normalization is the process of organizing data so that it is easy to find and use and is defined by an industry-specific common language. This can be accomplished by storing data in a central location, using consistent formatting, and using standardized terminology.
There are many benefits to data normalization, including improved decision-making, increased efficiency, and reduced costs. Let’s take a closer look at each of these benefits:
Improved Decision-Making
When data is normalized correctly, it is easier to find and use. This means that you will be able to make better decisions because you will have quick and easy access to the information you need.
How exactly does data normalization improve your company’s decision-making?
Data Accuracy
- The first way is by ensuring that the data is accurate. If the data is not accurate, it can lead to wrong decisions. Data normalization cleans and organizes the data so that you can be sure that the information you are using is correct.
Time-Saving
- The second way data normalization improves decision-making is by saving time. When data is not normalized, it can be time-consuming to find the information you need. This is because you will have to search through a lot of data that is not relevant to what you are looking for. Data normalization saves you time by organizing the data so that you can quickly and easily find what you need. Lastly, data normalization helps you to avoid duplication of data. Duplication of data can lead to inconsistency and errors. Data normalization ensures that there is only one version of the truth so that you can be confident in the decisions you are making.
Increased Efficiency
Normalizing data can also help increase efficiency by reducing the amount of time spent searching for data and correcting errors.
Data Normalization enhances efficiency in a number of critical ways:
– It improves communication by ensuring that all users are working with the same set of data.
– It eliminates duplicate data, which can save time and reduce storage costs.
– It ensures that data is entered correctly, which can save time and eliminate errors.
Enhanced Data Integrity
Data integrity is improved when data is normalized because it minimizes the number of places where data can be entered. This reduces the chances of errors and inconsistencies.
Examples of this are:
– Creating a unique ID for each customer instead of using multiple fields such as name, address, and phone number.
– Using a numeric value to represent a yes/no answer instead of using text values such as “Y” or “N.”
Normal Forms in Data Normalization
There are three normal forms in data normalization: first, second, and third. The higher the level of normalization, the more efficient the data will be.
Third normal form is the highest level of normalization and is typically used for data warehousing and decision support systems. In third normal form, all non-key fields must depend on the primary key.
Here is an example of data that is not in third normal form:
Client ID First Name Last Name Account 1 Account 2 Account 3
1001 John Smith TD Ameritrade ROTH Schwab Brokerage Pershing IRA
1002 Jane Doe Altruist ROTH Schwab JTWROS Interactive Brokers Brokerage
In this example, the Accounts are not dependent on the Client ID, which is the primary key. This data would need to be reorganized so that each account is listed separately and has its own Client ID.
Client ID First Name Last Name Account
1001 John Smith TD Ameritrade ROTH
1001 John Smith Schwab Brokerage
1001 John Smith Pershing IRA
1002 Jane Doe Altruist ROTH
1002 Jane Doe Schwab JTWROS
1002 Jane Doe Interactive Brokers Brokerage
Second normal form is typically used for transactional systems. In second normal form, all non-key fields must depend on the whole primary key.
Why would someone use the second normal form of data normalization?
There are a few reasons:
– To reduce the amount of duplicate data.
– To make it easier to update data.
– To make it easier to query data.
Why would you choose to use the third or first form of data normalization instead?
It really depends on the specific needs of your project. If you need to query data frequently, then the third form of data normalization would be a good choice. If you need to update data often, then the first form of data normalization might be a better choice.
The most important thing is to choose the level of normalization that makes the most sense for your project.
When you are designing a database, it is important to consider the different types of data that will be stored in it. This will help you to determine the level of normalization that is appropriate for your project.
For example, if you are designing a database to store client information, you will need to consider the types of data that will be stored in it.
Some of the data, such as name and address, will be used frequently. Other data, such as date of birth or gender, will be used less often.
You will also need to consider how often the data will be updated. For example, if you are storing client information, you will need to consider how often the data will be changed.
If the data is static and rarely changes, then you can choose a lower level of normalization. However, if the data is dynamic and changes frequently, then you will need to choose a higher level of normalization.
At Milemarker, we believe in generally using the third form to help you best normalize your data in a way that provides you a solid single source of truth, the proper primary keys, and better long-term data hygiene.
Here is an example of data that is not in second normal form:
Client ID First Name Last Name Account 1 Account 2 Account 3
1001 John Smith TD Ameritrade ROTH Schwab Brokerage Pershing IRA
1002 Jane Doe Altruist ROTH Schwab JTWROS Interactive Brokers Brokerage
In this example, the Accounts are not dependent on the Client ID, which is the primary key. This data would need to be reorganized so that each account is listed separately and has its own Client ID.
Client ID First Name Last Name Account
1001 John Smith TD Ameritrade ROTH
1001 John Smith Schwab Brokerage
1001 John Smith Pershing IRA
1002 Jane Doe Altruist ROTH
1002 Jane Doe Schwab JTWROS
1002 Jane Doe Interactive Brokers Brokerage
Second normal form is more efficient than first normal form but not as efficient as third normal form.
First normal form is the most basic level of data normalization. In first normal form, all non-key fields must depend on the primary key.
Here is an example of data that is not in first normal form:
Client ID First Name Last Name Account 1 Account 2 Account 3
1001 John Smith TD Ameritrade ROTH Schwab Brokerage Pershing IRA
1002 Jane Doe Altruist ROTH Schwab JTWROS Interactive Brokers Brokerage
In this example, the Accounts are not dependent on the Client ID, which is the primary key. This data would need to be reorganized so that each account is listed separately and has its own Client ID.
Client ID First Name Last Name Account
1001 John Smith TD Ameritrade ROTH
1001 John Smith Schwab Brokerage
1001 John Smith Pershing IRA
1002 Jane Doe Altruist ROTH
1002 Jane Doe Schwab JTWROS
1002 Jane Doe Interactive Brokers Brokerage
First normal form is the most basic level of data normalization and is typically used for transactional systems.
Eliminating Data Redundancy
Data redundancy is when the same data is stored in multiple places. This can lead to inconsistency and errors. Data normalization eliminates data redundancy by ensuring that there is only one copy of each piece of data.
Some examples of data redundancy are:
– Storing the same customer’s name and address in multiple databases.
– Saving the same image in multiple formats.
– Creating multiple copies of the same report.
Simplifying Database Structure
A well-designed database is easy to understand and use. Data normalization can help simplify the database structure by breaking down data into smaller, more manageable pieces. This makes it easier to find and use the data.
Some examples of how data normalization can simplify the database structure are:
– Breaking down a customer’s name into first, middle, and last names instead of storing it as one field.
– Dividing a customer’s address into separate fields such as street, city, state, and zip code.
– Splitting a date into the day, month, and year.
Customers working with Milemarker have been able to experience enhanced database structure by using Milemarker as a tool that provides the organization with a single source of truth, allowing for consistent data, relational data, and highly functional data that can be reconciled within the organization’s environment — supplying authoritative confirmation.
Total Database Normalization
Total database normalization is the process of reducing a database to its most basic form. All data is stored in one table with no duplication. This can be difficult to achieve and is not always necessary.
Reasons for total database normalization are multiple in financial services companies. In the post-merger environment, there is often a need to assimilate two different data sets into one quickly — and total normalization is often the quickest way to do this. Additionally, in order to meet compliance requirements, it might be necessary to show that data has not been manipulated — and the only way to guarantee this is through total database normalization.
Milemarker’s data management software is designed to provide complete normalization of your data, giving you the confidence that your data is accurate and reliable.
Partial Database Normalization
Partial database normalization is the process of breaking down data into smaller, more manageable pieces. This can be done by breaking down data into multiple tables.
Partial database normalization is often a good compromise between the need for simplicity and the need for efficiency. It can provide the benefits of both normalized and denormalized data without the drawbacks of each.
Some examples of partial database normalization are:
– Dividing a customer’s name into first, middle, and last names instead of storing it as one field.
– Dividing a customer’s address into separate fields such as street, city, state, and zip code.
– Splitting a date into the day, month, and year.
Milemarker offers a partial database normalization solution that can be customized to meet your specific needs.
Reduced Costs
Finally, data normalization can also help reduce costs by eliminating the need for duplicate data entry and storage.
How exactly do you achieve cost reduction when it seems like the amount of data you have only grows?
Data normalization helps reduce costs in a few key ways:
– It eliminates the need to store duplicate data, which can save on storage costs.
– It reduces the amount of time spent searching for data, which can save on labor costs.
– It minimizes the chances of errors, which can save on reprinting and redelivery costs.
Studies have shown that by normalizing your data, you can save as much as 30% on your overall costs. In fact, one study showed that a company saved $1 million per year simply by normalizing its data.
In Conclusion
Normalizing your company’s data can have many benefits, including improved decision-making, increased efficiency, and reduced costs. If your data is currently a jumbled mess, consider implementing some of these Data Normalization techniques to get organized.
Milemarker can help you achieve clear cost savings by providing a comprehensive solution for data normalization. We can help you organize your data, eliminate duplicates, and find the most efficient way to store and use your data.[/vc_column_text][/vc_column][/vc_row]
